캐시 성능
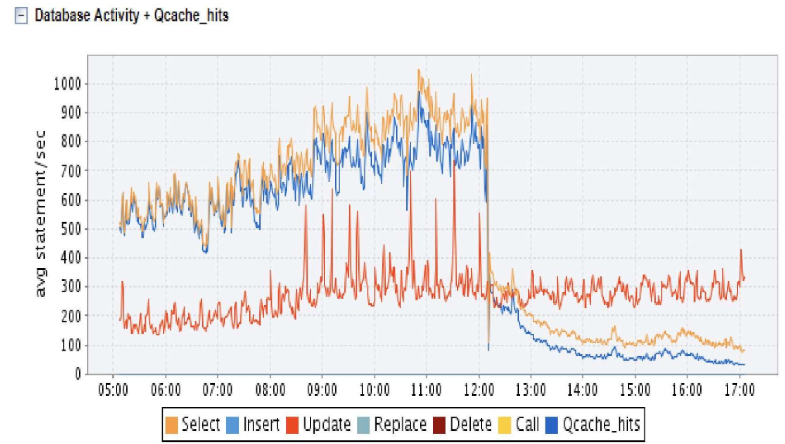
12:00가량에 캐시를 적용한 그래프다
- Select는 캐시히트가 발생하므로 DB에 쿼리 횟수가 감소한다
- 반면 Update는 어차피 DB에 접근을 해야 해서 변화가 거의 없다
- Select가 빠지면서 CPU 이용률이 감소한다.
- CPU 사용률 측정 등 성능 측정은 Locus, Gatling, Jmeter등을 많이 사용한다
데이터의 Scale Out
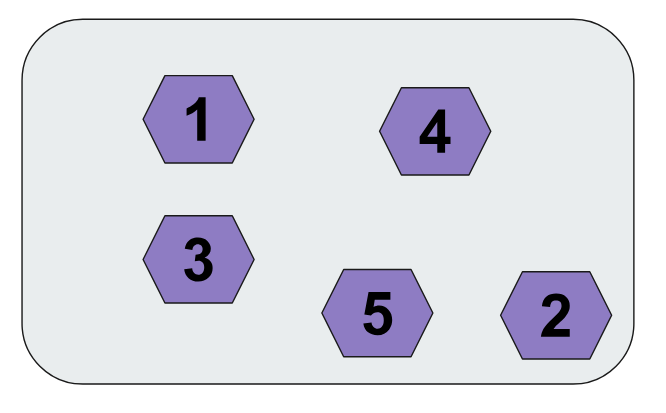
서버 2대에 데이터를 나눠서 담는 방법을 생각해보자.
- 위치 왼쪽 / 오른쪽
- 작은 숫자 / 큰 숫자
- %2 연산
이렇게 다양한 방법을 떠올릴 수 있다. 하지만 단순히 위치로 나누면 데이터의 위치를 파악할 수 없다. 따라서 전체를 찾아야 한다. 이런 일을 방지하기 위해서는 데이터를 나누는 규칙기준이 필요하다.
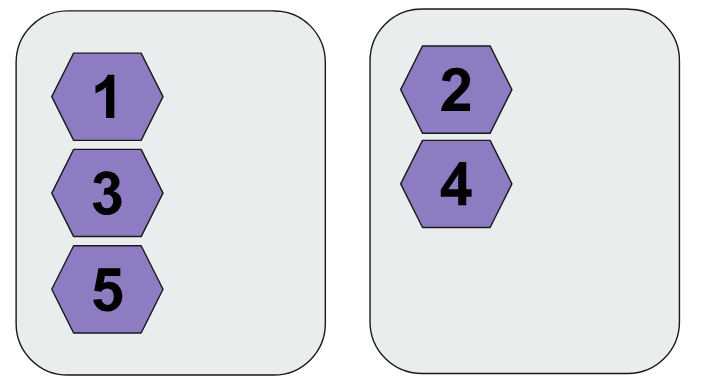
위와 같이 %2 연산의 결과로 나누기로 했다고 가정하자. 명확한 규칙이 있고 원하는 데이터의 위치를 알 수 있다.
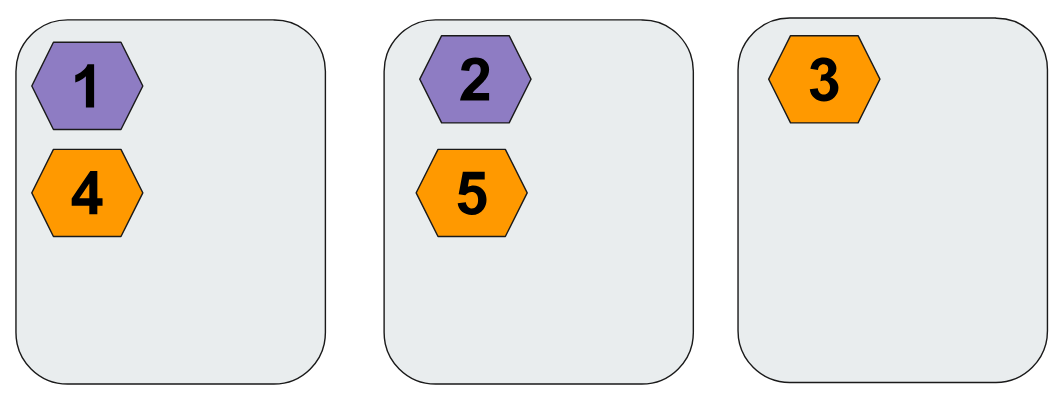
하지만 서버가 1대 증설되어 3개가 될 수 있다. 이런 경우 %3 연산을 사용할 수 있다. 규칙기준은 명확하지만, 이동하는 데이터가 많다. 이처럼 서버가 늘어날 때 마다 재배치하는 것은 안좋을 수 있다.
따라서 확장에 데이터가 적게 움직이는 방법을 사용해야 한다.
Redis에서 사용하는 다양한 데이터 배치 방법을 알아보자.
Redis with Range
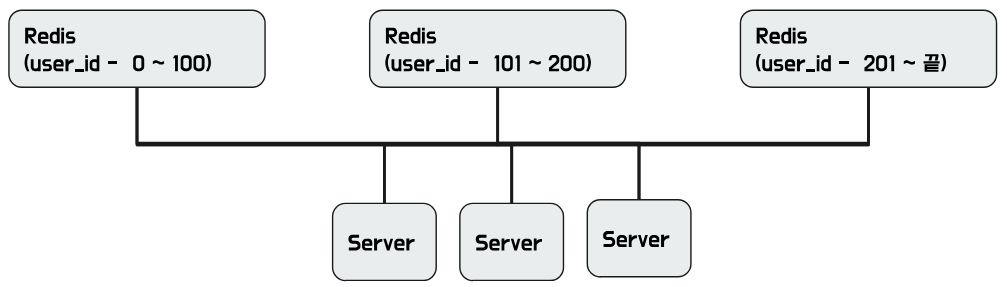
- 특정 key의 range로 구분하는 방법이다. 구현하기 쉬워 많이 사용한다
- Range별로 서버의 부하도가 차이날 수 있다. 예를 들어 이벤트 기간에 가입한 유저들은 특정 range에 몰릴 것이다. 이벤트가 끝나면 3%정도의 유저가 남고 해당 서버의 부하도가 낮을 것이다.
- 또한 변화가 한 서버에 집중될 수 있다.
Redis with PreShard
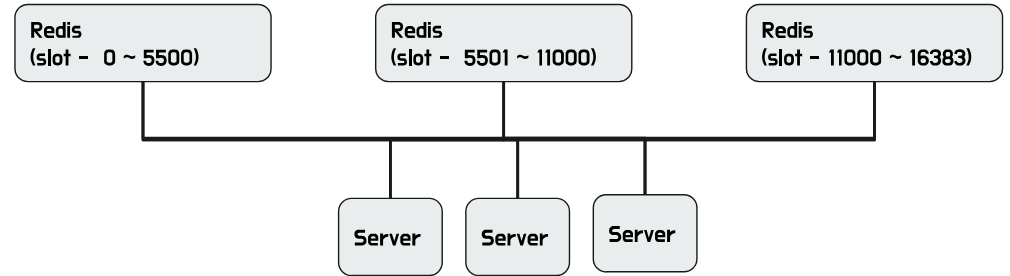
- hash(key)%16384와 같이 해시 후 모듈러 연산을 사용한다
- 그냥 해시나 모듈러에 비해 더 균등하지만 역시 재분배가 발생한다.
Redis with Consistent Hashing
Consistent hashing (Hash ring)
Consistent hashing은 Hashing을 일관되게 유지하는 방법이다. 이게 뭐다 라고 설명하기 보단, 먼저 상황을 예시로 들어보자. 노드 3개에 데이터를 분산 저장하는 상황이 있다. 제일 쉬우면서 분산저장
binux.tistory.com
Consistent hashing에 관해서는 위 글을 참고했다.
Consistent hashing은 hash ring을 사용하는 해시 방식이다.
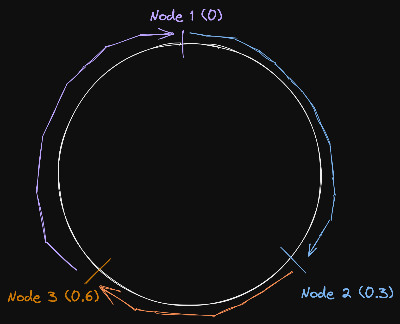
해시 연산 결과 0~1사이의 값이 나온다고 가정하자.
Data에 대해 해시연산한 값의 결과와 가장 가까운 노드에 데이터를 저장하는 것이다.
가장 가깝다는 것은 구현하기 나름이다. 해시 값 이상인 노드중 가장 가까운 노드, 즉 위 그림처럼 저장한다고 가정하자.
Consistent Hashing은 데이터 재배치 문제를 일부 해결한다.
- 노드 3개 -> 2개
- 노드 2가 사라진다면, 노드 2에 있던 데이터들만 모두 노드 3으로 재배치하게 된다. 모든 데이터를 재배치 할 필요가 없다. (노드 1이나 3에 있던 데이터는 이동 X)
- 노드 3개 -> 4개
- 노드 3과 노드 1 사이에 노드 4가 추가된다면, 노드3<해시값<=노드4 인 데이터들만 노드 4로 재배치하면 된다. 마찬가지로 모든 데이터를 재배치 할 필요가 없다.
반면 단점도 존재한다.
- Hash Ring의 노드 자체를 균등하게 구성하더라도 데이터는 균등하게 저장되지 않는다.
- 노드가 죽어서 데이터를 재배치할 때 특정 노드로 데이터가 몰려 과부하가 올 수 있다.
- 노드 2가 죽으면 노드 2의 데이터는 모두 노드 3으로 재배치된다. 노드 3에 과부하가 올 수 있다. 노드 3이 죽으면 노드 1에 모든 데이터가 재배치되고 과부하가 올 수 있다.
- 즉 연쇄작용을 통해 모든 노드가 죽을 수 있다. 이러한 문제를 해결하기 위해 vnode를 사용한다;
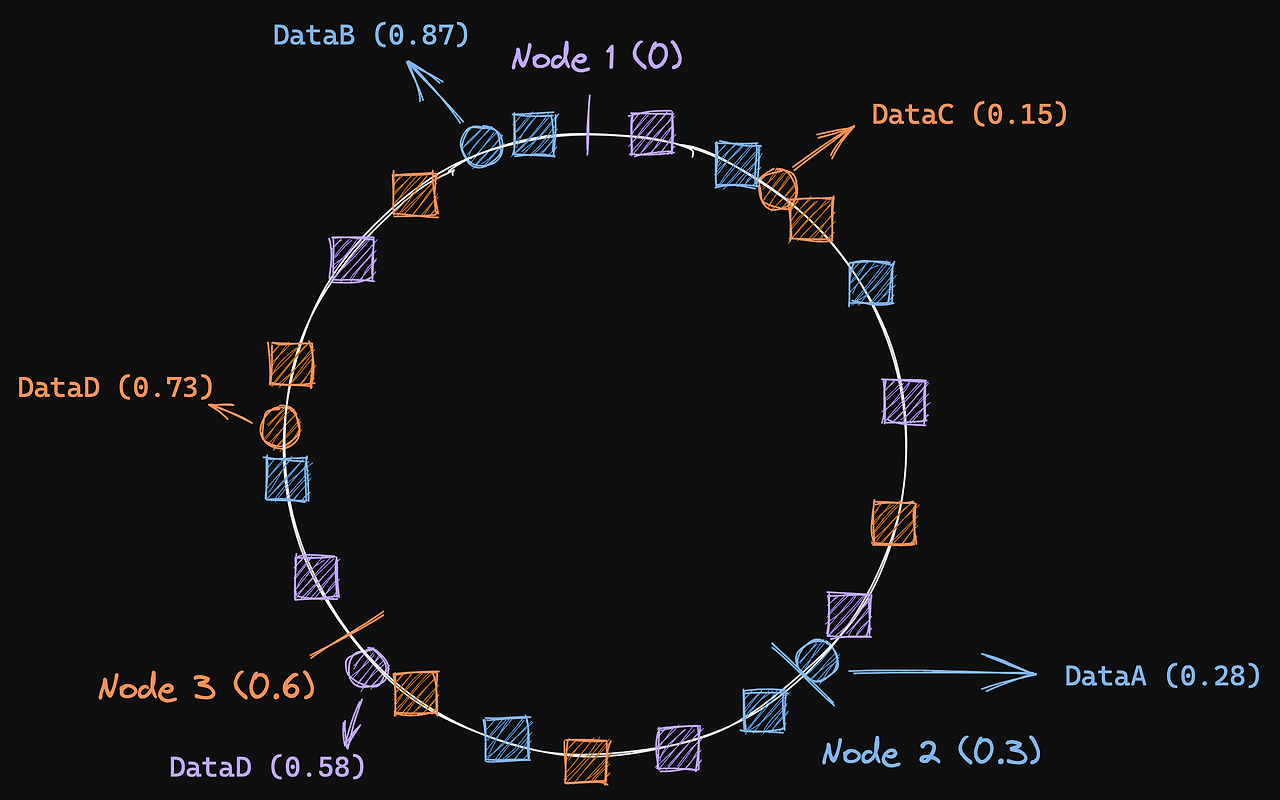
- vnode는 virtual node로, 노드를 나타내는 가상의 노드다.
- 각 노드마다 vnode 6개씩을 갖는다 가정하고 그 노드들을 범위상에 랜덤하게 뿌렸다. 데이터는 데이터의 해시 값 이상의 가장 가까운 vnode에 해당하는 노드에 배치한다. 더 다양하고 비정형화된 hash ring이 생성된다.
- 이전 방식에서는 노드 3이 사라지면 노드 3에 있던 모든 데이터가 노드 1로 재배치되어 노드 1에 과부하가 발생한다.
- vnode 방식에서는 노드 3이 사라지면 dataC는 노드 2로, dataD는 노드 1로 재배치된다. 즉 부하가 몰리지 않게 끔 재배치될 수 있다.
'데이터베이스' 카테고리의 다른 글
| 인덱스 (0) | 2024.11.21 |
|---|---|
| 서브쿼리 vs 조인 (0) | 2024.11.20 |
| JPA에서 식별 관계, 비식별 관계 중 무엇을 사용해야 할까? (2) | 2024.09.18 |
| Java의 DB 접근 방법 (0) | 2023.12.11 |

댓글