
네트워크는 복잡한 시스템이고 이것을 계층적으로 나누어 놓았다.
상위 계층일수록 개념적이고 하위 계층일수록 구체적이다.
transport layer 까지는 segment가 어떻게(어떤 경로로) 목적지를 향해 가는지는 관심이 없었다.
network layer에서는 그 얘기를 해야한다. IP가 그러한 일을 하는 프로토콜이다.
네트워크 계층이 이러한 일을 하므로 라우터에는 phyiscal, link, network 계층까지 존재하는 것이다.
nw layer가 하는 일
네트워크 레이어에서는 forwarding과 routing을 진행한다.
forwarding은 pkt 헤더의 목적지를 보고, 라우터의 forwarding table에서 그 목적지로 가려면
어느 outgoing link를 선택해야 하는지 보고 그곳으로 보내는 것이다.
forwarding table만 있으면 forwarding은 간단하다.
forwarding table을 만드는 것이 routing algorithm이 하는 일이다.
fowarding table

forwarding table에 모든 주소를 관리하기는 overhead가 크기 때문에 주소의 범위로 관리한다.
longest prefix matching

가장 구체적으로 맞는 주소를 선택한다는 것이다.
예시에서 2번째 DA는 2,3번째 범위에 맞지만 2번째가 더 구체적이므로 1 link interface를 선택한다.
ip header
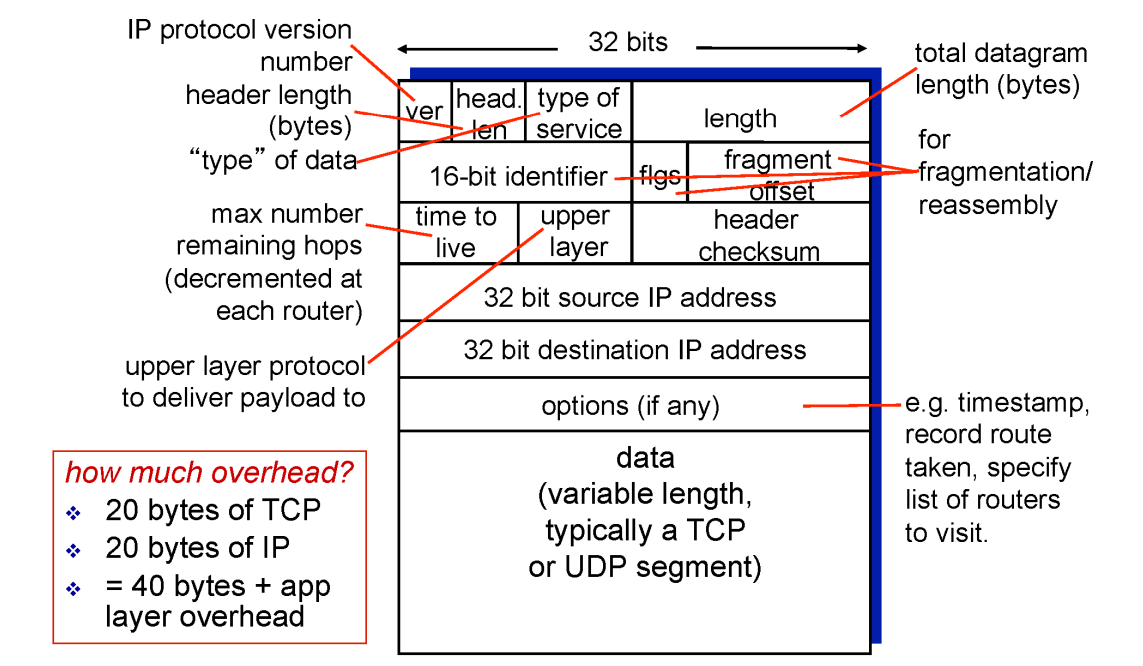
data에는 상위 계층인 transport 계층의 tcp나 ucp segment가 들어간다.
- ver : ip protocol 버전(현재4)
- length : pkt 길이
- src ip address : 메세지를 생성해서 보내는 사람의 ip 주소
- dest ip address : 목적지 ip 주소
- checksum : 에러체킹
- ttl(time to live): 라우터를 지날 떄마다 이 값에 -1 해준다. 0이되는순간 이 pkt을 버린다.
- 무언가 문제가 생겨 네트워크를 무한히 도는 경우를 막기 위해
- upper layer : data 부분에 들어가는 세그먼트가 tcp인지 ucp인지 여부
ip 헤더 20byte, tcp 헤더 20byte이다.
인터넷 대부분 pkt은 tcp pkt이고 40byte의 헤더를 갖는다.
tcp ack와 같은 pkt은 헤더만 존재하므로 전체 길이가 40byte이다.
ip address

32bit 주소값이다. 사람 입장에서는 12.34.158.5 와 같이 8bit씩 나눠서 10진수로 표현한다.
호스트의 주소를 의미한다. 사실 호스트의 nw interface를 지칭하는 주소다.
nw interface 카드를 여러개 사용하면 ip 주소를 여러개 사용할 수 있다. 대표적으로 라우터이다.
계층적 addressing
ip 주소를 막무가내로 배정하면 라우터의 forwarding table의 엔트리가 커서 메모리, 검색 overhead가 커진다.
따라서 계층화된 주소를 사용한다.

앞부분은 nw id, 뒷부분은 host로 나눴다. 같은 nw에 속하면 nw id가 같다.
nw id는 subnet id, prefix라고도 부른다.
12.34.158.0/24의 표현방식에서 24가 nw id의 비트길이를 의미한다. 다만 이것은 사람을 위한 표시다.

컴퓨터를 위해서는 subnet mask를 통해 어디까지가 nw id인지 표시한다.
항상 ip 주소와 subnet mask는 함께 표시해준다.

같은 nw에 속하면 같은 prefix를 갖게 해서 scalability가 향상되고 forwarding table이 단순해졌다.
ip의 과거
인터넷은 nw들을 묶어놓은것이다. 즉 nw들의 nw이다.
각 nw는 자신의 prefix를 가져야 한다. 그 prefix의 길이는 제각각일 것이다.
classful addressing

과거에는 class 별로 주소를 매겼다.
Class A는 할당받을 수 있는 기관이 적지만 사용할 수 있는 host가 많다.
Class C는 할당받을 수 있는 기관이 많지만 사용할 수 있는 host가 적다.
비효율적이어서 지금은 사용하지 않는다.
왜냐하면 만약 1000개의 host가 필요하면 class C로 4개의 ip prefix를 할당받아야 한다.
그만큼 routing table entry도 많아지게 된다.
cidr

그래서 cidr을 도입한다. (classless inter domain routing)
원하는 길이만큼의 prefix를 사용할 수 있다. 그리고 그 길이는 mask로 알려준다.
이 방식을 사용하면 nw 안의 router들의 fowrarding table의 크기도 감소한다.
longest prefix matching

matching이 여러개 될 경우 prefix의 길이가 가장 긴 것이랑 matching시킨다.
3번째와 4번째가 201.10.6.16과 matching이 되지만 4번째가 prefix가 더 길기 때문에 선택된다.
라우터가 하는 일이 longest prefix matching을 계속 하는것이다.
subnet

subnet은 같은 prefix를 갖는 device의 집합이다.
같은 subnet에서는 router를 거치지 않고 서로 접근할 수 있다.
라우터는 여러개의 ip를 갖는다. 이 ip들은 prefix가 제각기 다르다.
따라서 router는 여러개의 subnet에 속한다. subnet끼리 연결하는 역할을 한다.
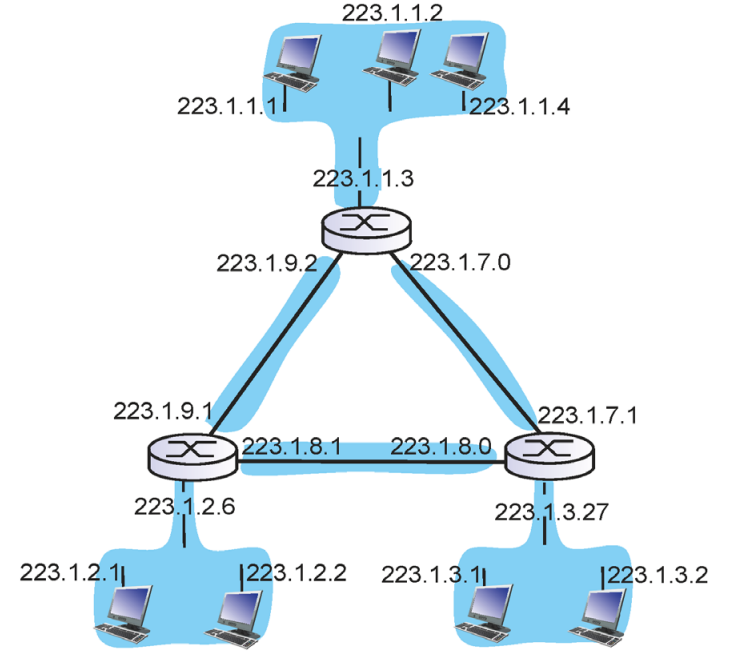
위 예시는 6개의 subnet을 갖는다. (/24 라고 가정)
nat
ipv4는 2^32로 약 40억개의 주소를 지원한다.
인터넷 상업화 이후 이것이 부족할 것이라고 생각해 2^128의 주소공간을 지원하는 ipv6을 출시했다.
하지만 현재 ipv4를 계속 사용하고 있다. 이것은 network address translation , nat 로 인해 가능하다.
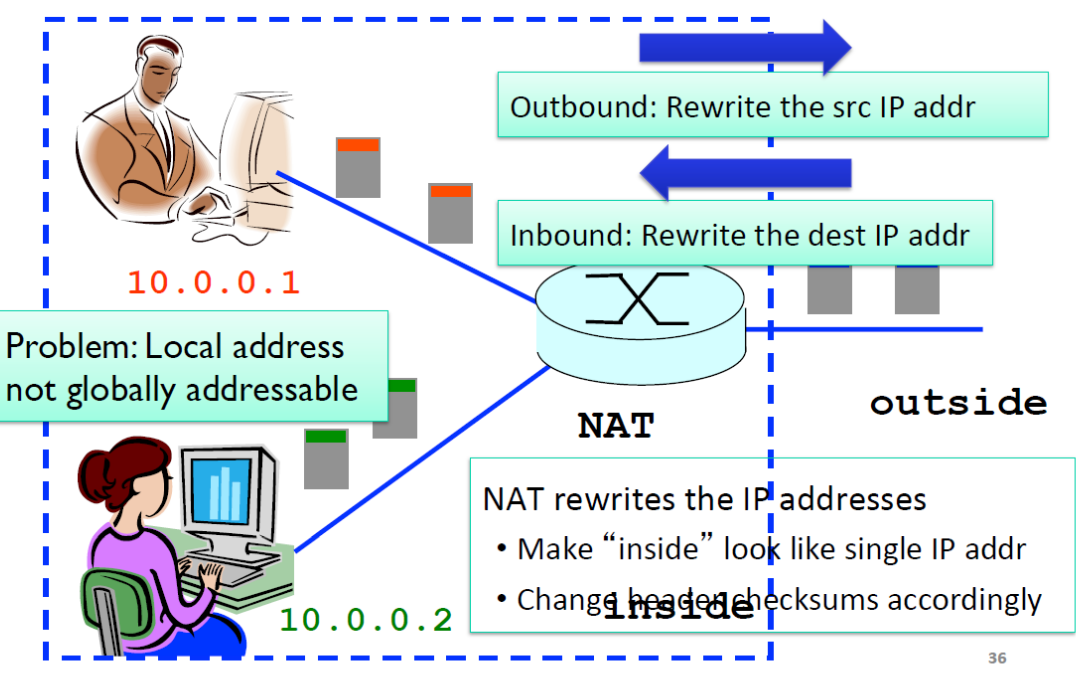
nw 내부에서 사용하는 ip는 nw 내부에서 고유하다. 다른 nw에서는 이 ip를 사용할 수 있다.
nw 밖으로 나갈때는 nat에 의해 gateway router의 주소로 변환을 해서 내보낸다.
반대로 nw 안으로 packet이 들어올 때도 nat에 의해 nw 내부의 ip로 변환한다.

동작방식
local nw안에서는 각자 고유한 ip를 사용한다.
하지만 local nw 외부에서는 이것이 고유하지 않다. 따라서 답장이 올 때 문제가 된다.
local nw 를 나갈 때는 모두 같은 src ip 주소를 갖게 된다. (라우터의 ip 주소, 이것은 세계에서 유일함)
gateway router가 src ip 주소와 port#를 변환해준다.
port#를 변환하는 이유는 10.0.0.1의 프로세스와 10.0.0.2의 프로세스가 같은 port#를 사용할 수 있기 때문이다.
ip 주소는 host마다 다르고, port#는 같은 host 내에서 process를 구분하는 역할이다.
즉 10.0.0.1도 port80에서 pkt이 나가고 10.0.0.2도 port80에서 pkt이 나가는 상황에서 gateway router의 ip로 src ip가 변경되면 local nw의 두 ip를 구분할 방법이 없으므로 port#도 변환해줘야 한다.
local nw로 들어오는 pkt도 gateway router의 ip를 dest ip값으로 갖는다.
port#로 local nw에서 어떤 ip주소로 가야할 지 결정한다.
단점
- nw layer device인 router가 transport layer인 tcp hdr의 port#값을 변경한다
- port#은 원래 같은 ip에서 process를 구분하기 위해 사용하는데, nat을 사용하면 이것이 host 구분에 사용된다.
- 이러한 이유로 nat을 사용하는 local nw에서는 서버를 운용할 수 없다.
ipv4가 갖는 문제인 주소공간의 부족은 nat으로 해결하지만 이러한 단점이 있고 임시방편적이다.
ipv4는 역시 security 문제도 갖고 있다.
ipv4의 설계 당시 생각하지 못했던 요구사항들 때문에 문제가 발생하고 있고 임시방편적인 방법으로 해결하고 있다.
따라서 ipv6로 넘어가거나 다른 어떤 protocol로 넘어가야 한다.
하지만 바꾸는게 쉽지 않다. router의 소유자들이(통신사) 모두 다르기 때문이다.
dhcp

인터넷을 하기 위해 필수적으로 4가지 정보가 필요하다.
- 나의 ip와 mask
- 라우터의 ip
- 라우터가 이 subnet에서 가장 중요해서 host 1번을 먹었다.
- dns
- 내가 naver로 요청을 보내고 싶으면 naver의 ip 주소를 알아야 한다. name server에게 물어보는데, 이 name server의 주소다.
- 위 예시에서는 router와 dns의 주소가 같다. 즉 router에 name server가 위치한다.
dynamic host configuration protocol, dhcp에 의해 이러한 정보가 쓰여진다. 어느 곳에 가던, 동적으로 써준다.
물론 고정 ip를 쓰는 경우도 있다. 유동 ip인 경우에 dhcp를 쓰는 것이다.
고정 ip를 사용하면 nw 안에 사용자 수 만큼 ip가 필요하다. 만명의 host가 있으면 만개의 ip가 필요하다.
하지만 동적 ip를 사용하면 1000개를 돌려가며 사용할 수 있다. 이런 점이 dhcp의 유용성이다.
다만 사용한 ip를 회수하는 과정이 필요하다.

새로운 클라이언트 박거성이 nw에 추가되는 상황이다.

박거성은 가진 정보가 없기 때문에 도움을 요청하는 메세지인 dhcp discover를 보낸다.
src : 0.0.0.0 (나의 ip를 모름)
dest : 255.255.255.255 (broadcast, subnet의 모두에게 보내는 메세지)
transaction id : 박거성이 정한 임의의 값
모두에게 이 최초 메세지가 가는데, dhcp 서버만 port67을 열어놓아서 이 메세지를 받는다.
나머지 호스트들은 port67을 열어놓지 않아 메세지를 무시한다.
dhcp server는 dhcp offer를 보낸다.
offer의 dest가 broadcast인 이유는 아직 박거성의 ip가 할당되지 않았기 때문이다.
역시 port68을 열어놓은 박거성만 이 메세지를 받아들인다. (transaction id로도 판별)
yiaddr : 박거성에게 부여하는 ip
lifetime : 1시간동안 사용
이런 정보 뿐만 아니라 router의 ip, dns의 ip등을 알려준다.
dhcp offer에 대한 응답으로(수락의 의미) dhcp request를 보낸다.
src : 0.0.0.0 박거성의 ip가 아직 확정된게 아니다.
transaction id : 전 값에 1 더한 값
dhcp ack까지 끝나게 되면 박거성은 자신의 ip, router의 ip, dns의 ip등을 알게 되고 사용한다.
dhcp offer까지만 하고 끝내지 않는 이유는, nw상에 dhcp server가 2개 이상일 수 있다.
그럴 경우 offer가 2개 이상이 오게 되고 박거성은 맘에 드는 offer를 선택하면 된다 .
이러한 이유로 dhcp request의 dest가 broadcast인 것이다.
모든 dhcp server에게 박거성이 어떤 offer를 수락했는지 알려야 하기 때문이다.
일반적으로는 gateway router에 dns process와 dhcp server가 위치한다.
따라서 gateway router에는 dns, dhcp, nat, firewall(추후에 배움) 까지 위치하게 된다.
박거성이 최초에 nw에 합류하면 dhcp에 의해 인터넷에 필요한 주소들에 대해 알게 된다.
박거성이 naver에 요청하면 dns가 naver의 ip를 알려주고 박거성이 보낸 pkt은 nat에 의해 변환되어 송신된다.
실생활에서 우리가 무선 공유기를 사용하는 상황을 생각해보자.
skt에서는 우리 집에 ip 하나를 할당해준다.
엄마, 아빠, 나는 공유기를 통해 무선으로 이 ip를 공유해서 쓴다.
즉 공유기가 gateway router인 것이고 nat, ns, dhcp 등이 작동한다.
공유기, 엄마, 아빠, 내가 하나의 subnet을 구성한다.
공유기 밖으로 pkt이 나갈 때는 nat에 의해 하나의 ip로 나가게 된다.
그럼 우리집 공유기 iptime의 ip는 전세계적으로 유일할까? 유일할 것 같지만 사실 모르는 일이다.
왜냐하면 iptime이 속한 subnet의 router에서 또 nat를 사용할 수 있기 때문이다.
fragment, reassemble
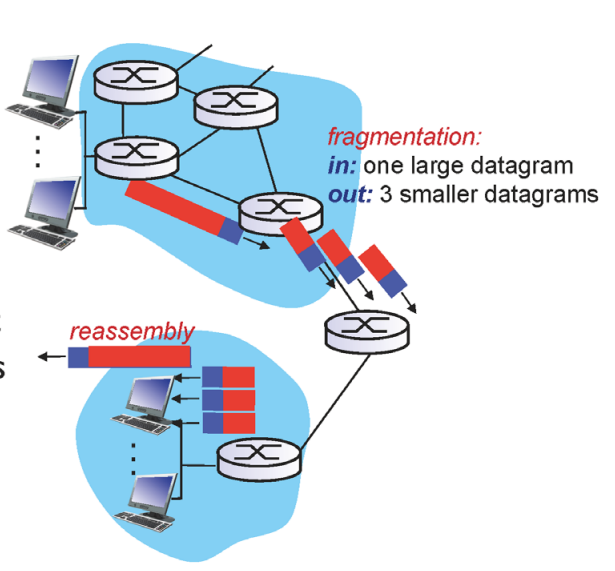
ip pkt이 mtu(link가 한번에 보낼 수 있는 최대크기)를 초과하면
fragmentation에 의해 pkt을 분리하고 도착지에서 reassemble한다.
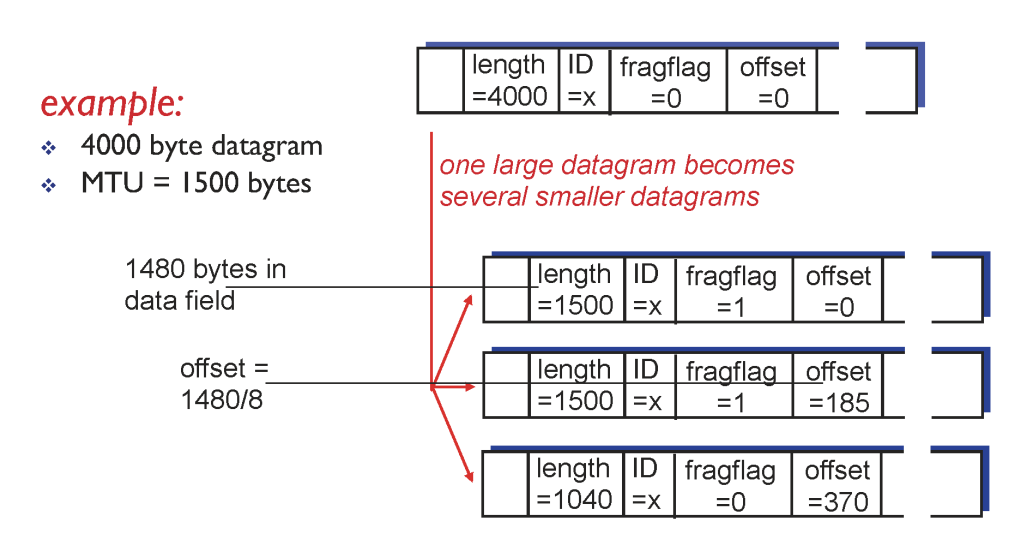
ip hdr의 id, flag, offset 값이 이 과정을 위해 있다.
id는 sender가 임의로 정한 값이다. 이 값을 통해 나중에 reassemble한다.
flag는 내 뒤로 내가 쪼개진 pkt이 있는지를 의미한다.
offset은 이 pkt의 data 시작 위치이다.
나눠지기 전 pkt은 4000byte length에 flag 0 offset 0이다. 4000중 앞 20은 hdr이다. (ip pkt의 hdr는 20byte)
mtu가 1500이므로 pkt을 나눈다.
나눠진 후 첫번째 pkt은 flag 1 offset 0이다. 그리고 hdr 제외 1480만큼의 data를 담는다.
두번째 pkt은 1480부터 data가 시작한다. bit수를 줄이기 위해 /8 해서 적는다. (1480/8=185)
세번째도 같은 원리이다.
이러한 정보들이 있어서 reassemble이 가능한 것이다.
만약 분리된 pkt중 일부만 loss가 발생한다면?
nw layer에서 pkt을 reassemble 하지 못해 transport 계층으로 못올린다. 따라서 timeout이 발생한다.
따라서 transport layer에서 재전송하는 절차를 밟는다.
icmp
icmp는 control message를 운반하기 위한 프로토콜이다.
control message는 사용자가 생성한 data가 아닌 nw 자체에서 발생한 메세지를 의미한다.

예를 들어 ip hdr의 ttl 필드값이 0이 되면 라우터에서 src에게 control msg를 만들어 report 한다.
data는 비어있고 hdr만 있으며 type 11 code 0이 된다.
ctrl msg 발생 원인마다 type-code가 정해져 있다.
tracerout

tracerout를 사용하면 특정 주소로 pkt을 보낼 때 거쳐가는 router 목록을 얻을 수 있다.
이 때 icmp를 사용한다.
pkt의 ttl을 1로 해서 보내면 첫번째 router에서 icmp msg가 오고
ttl 2로 하면 2번째 router에서 icmp msg가 오고.. 이것을 반복한다.
ipv6

ipv6로 변환할 지 안할지 모르기 때문에 간단하게만 다룬다.
address가 128bit이다.
flow label 과 같이 선언만 해놓고 어떻게 쓸 지 협의되지 않은 헤더들도 있다.
tunneling

ipv4에서 ipv6로 넘어가는 과도기를 상상해보자. 일부 라우터만 ipv6를 이해할 수 있다.
이럴 경우 ipv4와 ipv6를 모두 이해할 수 있는 라우터가 tunneling을해줘야 한다.
tunneling은 ipv4의 pkt에 ipv6를 넣어서 ipv4 라우터가 이해할 수 있게 하는 것이다.
routing algorithm
목적지까지 최소 cost의 algorithm을 찾아서 forwarding table을 만들어야 한다.
접근방법은 2가지가 있다
- 전체 그래프 구조를 아는 상황
- link state
- 모든 node들이 자신의 link 정보를 broadcast 한
- link state
- 이웃 라우터에 대해서만 아는 상황
- distance vector
link state algorithm
다익스트라랑 똑같다.
핵심은 그래프에 대한 정보를 알고 시작한다는 것이다.

집합 N'에 속한 노드는 그 노드까지의 최단거리가 확정된 것이다.


step 1
N'에 속하지 않고 가장 거리가 가까운 노드 선택(w)
w를 N'에 포함시킴
N'에 속하지 않으면서 새로 포함시킨 노드(w)와 인접한 노드들의 거리를 update한다.
D(v) = min(D(v),D(w)+c(w,v))
이 과정을 N'에 모든 노드가 포함될 때까지 반복하면 된다.

이렇게 u에서 모든 node로 가기 위한 최단경로를 구할 수 있다. 이걸 토대로 forwarding table을 만들면 된다.
각각의 router들이 자신의 입장에서 다익스트라를 돌려서 자신의 forwarding table을 갖게 된다.
link state algorithm의 범위는 하나의 소유권을 갖는 nw 안이다.
전체 인터넷을 한번에 하는것은 현실적으로 불가능하다.
하나의 nw 안에서는 link state를 쓰던 distane vector를 쓰던 소유주의 맘이다.
하지만 nw에서 nw를 거쳐가면 누군가 소유한게 아니기 때문에 이것을 결정하는 규칙이 따로 있다.
distance vector
전체 graph의 정보를 알지 못하고 내 이웃한 router 에 대해서만 알 수 있다.

c(x,v)는 이웃한 라우터간의 비용이므로 아는 값이다.
dv(y)는 재귀적으로 구할 수 있다.
이웃한 라우터가 자신이 계산한 distance 값들을 알려줘야 한다.
이 디스턴스 값의 array(vector)를 전달받아서 계산하기 때문에 distance vector algorithm이다.
이웃한 라우터가 전달해준 distance vector를 가지고 내 값을 계산했을 때,
변동이 있다면 내 이웃 router들에게 distance vector를 전달해야 한다.
이러한 과정을 stable해질 때까지 반복하면 된다.


최초에는 자기 자신, 자신과 이웃한 라우터까지의 cost만 안다.

이웃 라우터들의 distance vector를 전달받는다.
전달받은 값을 토대로 내 distnace vector를 업데이트 할 수 있다.

위 식에 따라 업데이트한다.
dx(y) = min{c(x,y)+dy(y), c(x,z)+dz(y)}이다.
c(x,y)=4, c(x,z)=50은 이미 아는 값이다.
dy(y)와 dz(y)는 전달받은 y와 z의 distance vector로 알 수 있다. 새로 구한 dx(y)=4이다.
기존 값과 같기 때문에 업데이트 할 필요가 없다.
같은 방식으로 dx(z)=5를 얻는데 이전 값인 50보다 작기 때문에 업데이트한다.
각 라우터들은 같은 방식으로 자신의 테이블을 업데이트한다.
자신의 테이블이 업데이트 되었다면 이웃한 라우터들에게 distance vector를 전달한다.

최종적으로 x,y,z의 distance vector가 모두 변하지 않는 안정화 된 상태를 얻는다.
count to infinity
table이 전부 stable 해진 상황에서, x와 y사이의 cost가 바뀌는 상황을 가정해보자.
cost가 1로 작아질 수 있다.
작아지는 경우 해당 link에 연결된 x와 y가 자신의 distance vector를 다시 계산한다.
dy(x) = min{c(y,x)+dx(x), c(y,z)+dz(x)} = min{1+0, 1+5}=1이다.
따라서 y의 distance vector가 업데이트되고, 이웃한 라우터들에게 전달한다.
dx(y) = min{c(x,y)+dy(y), c(x,z)+dz(y)} = min{1+0, 5+1} = 1이다. x역시 마찬가지로 이웃한 라우터들에게 전달한다.
값들을 전달했으므로 각 라우터에서는 dv를 새로 계산한다. x와 z의 dv가 변경되고 다시 전파한다.
이후로는 stable한 상태가 되어 변화가 없다. 즉 2번만 계산하면 stable한 상태가 된다.

반면 cost가 50으로 높아질 수 있다. 이 경우에는 위와 같은 과정을 거치게 된다.
이러한 문제가 발생하는 이유는 dz(x)가 사실은 z->y->x, 즉 y를 거쳐 가는 경로의 최소값이기 때문이다.
이 사실을 y는 모르기 때문에 이러한 반복이 발생하게 된다. 이것을 count to infinity라 한다.(bad new travels slow)
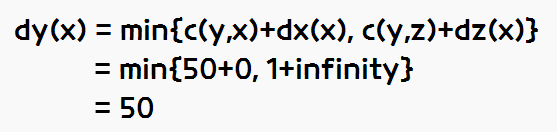
count to infinity를 해결하기 위해서는 dz(x)가 y를 통한 경로일 경우 y에게는 무한대라고 알려주면 된다.
dz(x)는 사실 z->y->x로 이 dv값을 알려줄 y를 거쳐가는 경로이므로 infinity로 알려준다.
이것은 y 입장에서 아무런 손해가 아니다.
왜냐하면 y는 이미 z가 알려주려던 경로인 z y x에 포함되는 y x를 알고 있기 때문이다.
물론 dz(x) 값을 x한테 넘겨줄때는 정상적으로 넘겨준다.
자신이 지나가는 경로에 포함되는 y에게 넘겨주는 경우만 infinity로 주는 것이다.
hierarchical routing

한양대, 동국대, 구글처럼 하나의 도메인에서는 자체적으로 정한 라우팅 방식을 사용한다.
이러한 도메인 하나를 as, autonomous system이라 부른다.
각 도메인에서 정한 라우팅 방식을 intra as algorithm이라 부른다. link state나 distance vector가 되겠다.
반면 as간의 라우팅 알고리즘을 inter as algorithm이라 부른다.
한양대에서 google로 pkt을 보낸다면, 한양대의 gateway router까지는 한양대의 intra as algorithm을 사용한다.
외부에서는 inter as algorithm을 사용해서 google까지 도착한다.
구글의 gateway router에 진입하고 google의 host까지는 google의 intra as algorithm을 사용한다.
이처럼 라우팅 방식이 계층적으로 되어 있어서 계층적 라우팅이라 한다.
as
as는 하나의 routing domain에 대한 자치권을 가진 system이다.
각 as는 고유번호를 부여받는다.

as 사이에는 provider-customer 관계가 존재한다.
as 는 자선단체가 아니다. 돈을 받아서 as를 운영하고 서비스를 제공한다.
한양대학교 as 혼자서 인터넷 서비스를 제공할 수 없다.
한양대 as는 skt as의 customer가 된다. skt는 provider가 된다.
쉽게 갑을관계라고 생각해도 된다.
한양대학교는 skt로부터 서비스를 제공받아야 한다. 반면 skt는 한양대에게 원하는게 없다.
따라서 skt가 갑, 한양대가 을이다.

하지만 skt랑 kt가 협상한다고 생각해보면 갑을관계가 명확하지 않다.
따라서 peer 관계를 맺는다.
peer는 동등한 관계로, 서로 돈을 주고받지 않고 win-win하는 관계다.
traffic을 돈의 관점에서 생각해보자. traffic을 보낼 때 누군가는 이득을 봐야한다. 그래야 traffic이 허용된다.
파란색 traffic은 항상 이득보는 주체가 있다.
반면 검은색 traffic은 허용되지 않는다. 왜냐하면 가운데 있는 as가 저걸 보내줌으로써 받는 이득이 없다.
bgp-4
- border gateway protocol
- policy based
- intra routing은 cost가 최소가 되는 것을 목표로 한다
- inter routing에 쓰이는 bgp는 정책에 따라 구현된다

AS는 prefix로도 나타낼 수 있다.
AS 6341이 자신의 prefix를 advertise하는 상황이다.
최초에는 as path에 자신의 as 번호를 넣는다. (6341)
전파될 때마다 다른 값은 유지하되 as path에 자신의 as number를 추가한다. (7018 6341)
즉 as path 필드의 원소 개수는 목적지까지의 as 개수를 의미한다. 그리고 어떤 as가 있는지 알 수 있다.
삼성이 at&t research로 pkt을 보낸다면 두 경로가 있는데, 두 경로의 as 수는 같다. 하지만 as의 수는 고려대상이 아니다.
경로를 선택할 때는 정책적으로 (삼성전자가 구글이 싫다면 다른 경로로 보낸다던지) 선택한다.
나한테 금전적으로 최대 이득을 볼 수 있는 경로로 보낸다.
Customer > Peer > Provider
따라서 내 입장에서 위와 같은 우선순위로 선택한다.

5 1 또는 4 1이 더 적은 수의 as를 거치는 경로다.
하지만 한양대학교는 3 2 1 path를 선택한다.
왜냐하면 hyu 입장에서 customer로만 구성되어서 금전적으로 이득이기 때문이다.
as의 수는 고려대상이 아니다.

댓글