https://core.ewha.ac.kr/publicview/C0101020140318134023355997?vmode=f
반효경 [운영체제] 5. Process1
설명이 없습니다.
core.ewha.ac.kr
프로세스란 ?
Process is a program in execution
프로세스는 실행중인 프로그램을 의미한다
프로세스의 문맥 context
단어의 정확한 의미를 파악하기 위해서는 문장 속에서 문맥을 파악해야 한다.
프로세스의 문맥도 마찬가지다.
프로그램이 태어나서 실행되다가 종료되는데 문맥은 그 중간 어느 시점을 잘라놓고 봤을 때 이 프로그램이 무엇을 어떻게 실행했는지, 현재 시점에 어떤 상태에 있는지 나타내기 위해 사용되는 개념이다.
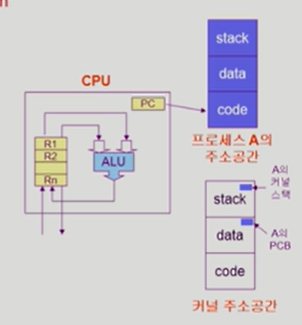
프로세스는 실행되면 프로세스만의 독자적인 주소공간을 형성한다. (code, data, stack)
프로세스가 CPU를 잡게 되면 PC 레지스터가 code의 어느 주소를 가리킨다.
그 주소에서 기계어 instruction을 하나씩 읽어서 CPU 안으로 불러들인다. 레지스터에 instruction을 넣고 산술연산장치 ALU에서 연산을 하고 결과를 레지스터나 바깥 메모리에 저장한다.
이러한 과정으로 프로세스가 실행되는데 프로세스가 현재 시점에 어디까지 와 있는지 판단하기 위해 필요한 정보가 프로세스의 문맥이다.
즉 프로세스의 현재 상태를 나타내는데 필요한 모든 정보를 프로세스의 문맥이라 한다.
문맥은 3가지가 있다.
✅ 하드웨어 문맥
CPU와 관련된 하드웨어 문맥
Process는 CPU를 잡고 매 순간 instruction을 실행한다.
현재 시점에 process가 instruction을 어디까지 수행했는지 알기 위해서는 레지스터의 값과 pc의 값을 알아야 한다.
주로 레지스터가 현재 어떤 값을 가지고 있었는가를 나타냄
✅ 프로세스의 주소 공간
code, data, stack에 어떤 값들이 들어가 있는가?
✅ 프로세스 관련 커널 자료구조
PCB : process control block : 프로세스에게 CPU, 메모리를 얼마나 줘야 할지 관리한다.
Kernel Stack : 어떤 프로세스가 system call을 했는지에 따라 커널 스택을 별도로 둔다.
현대 컴퓨터 시스템에서는 time sharing, multi tasking, 즉 프로세스들이 번갈아 가며 실행된다.
하나의 프로세스가 CPU를 잡고 실행을 하다가 다른 프로세스에게 CPU가 넘어가면서 작동한다.
프로세스의 context를 기억해놓지 않으면 다시 CPU를 잡았을 때 처음부터 다시 실행해야 한다.
문맥을 알아야 전에 실행하던 바로 다음 시점부터 실행할 수가 있다.
프로세스의 상태
프로세스는 상태가 변경되며 수행된다
✅ Running
CPU를 잡고 instruction을 수행 중인 상태
✅ Ready
CPU를 기다리는 상태 (메모 등 다른 조건은 모두 만족한 상태로 기다리는 것 )
✅ Blocked (wait, sleep)
CPU를 줘도 instruction을 수행할 수 없는 상태
IO를 기다리는 상태 (예) 디스크에서 파일을 읽어와야 하는 상태
경우에 따라서는 아래 2가지 상태도 고려한다.
✅ New
프로세스가 생성중인 상태
✅ Terminated
수행이 끝난 상태

프로세스 생성 -> ready(명령 실행에 필요한 최소한의 메모리는 가지고 있는 상태) -> running ->
IO같은 오래 걸리는 작업을 해야 한다 (자진해서 CPU 반납) or Timer interrupt 발생 (CPU 뺏김)
-> CPU를 얻고 잃음을 반복하다가 terminated

CPU는 빠르고 여럿이 공유하는 자원이다.
하나의 process가 CPU에서 running을 하고 있다가 timer interrupt가 들어오면 CPU를 뺏기고 ready queue의 맨 뒤로 이동해서 기다리게 된다.
또는 running을 하다가 DISK IO를 해야 한다면 CPU를 뺏기고 Disk IO Queue에 줄서게 된다.
IO작업이 끝나면 IO device controller가 CPU에 interrupt를 건다.
CPU는 인터럽트에 의해 하던 작업을 멈추고 제어권이 운영체제 커널에게 넘어가게 된다.
운영체제 커널은 프로세스 메모리 영역에 필요한 데이터를 넘겨준다.
그리고 blocked 상태인 프로세스를 ready로 바꿔서 CPU를 얻을 수 있는 자격을 준다.
자원 중에는 SW 자원, 공유데이터도 있다. 공유 데이터를 여러 프로세스가 동시에 접근하면 일관성이 깨지는 문제가 발생할 수 있다.
어떤 프로세스가 공유데이터를 접근하고 있으면 다른 프로세스는 공유자원 queue 에서 기다리게 되고 blocked 상태가 된다.
blocked 된 원인이 무엇인지에 따라 해당하는 queue (resource queue, IO queue)에 줄서있게 되고, 작업이 해결되면 ready queue로 넘어와 CPU를 얻을 수 있게 된다.

queue는 실제로 kernerl address space의 data 공간에서 관리하는 것이다. 프로세스들의 상태에 따라 CPU를 주고 말고 등을 관리한다.
PCB : Process Control Block
운영체제가 각 프로세스를 관리하기 위해 프로세스당 유지하는 정보이다.
구조체로 관리된다.

(1) OS가 관리상 사용하는 정보
process state : 프로세스의 상태, ready ,blocked
process id : 주민번호
scheduling information, priority : 프로세스에게 CPU를 주기 위한 우선순위나 스케줄링 정보가 있다. 꼭 queue에 먼저 온 프로세스에게 CPU를 먼저 주는 것은 아니다.
(2) CPU 수행 관련 하드웨어 값
프로세스의 문맥을 표시하기 위한 정보들
pc, register
(3) 메모리 관련
code, data, stack이 메모리 어디에 위치해 있는가
(4) 파일 관련
프로세스가 오픈하고 있는 파일들
- pc (program counter) 란 ?
- cpu는 여러가지 레지스터가 있다. 레지스터는 데이터 또는 주소를 일시적으로 보관한다.
- cpu가 메모리에서 데이터를 가져오는 것 보다 레지스터에 저장해놓고 사용하는 것이 빠르기 때문에 사용한다
- pc는 cpu에 있는 여러 레지스터 중 하나로, 다음번에 실행할 명령어의 주소를 저장하는 역할을 한다.
문맥 교환 context switch
CPU는 굉장히 빠른 장치이므로 프로세스는 계속 CPU를 얻었다가 뺏겼다가를 반복하게 된다.
CPU를 다시 얻으면 처음부터 실행하는게 아니라 뺏긴 시점의 문맥을 기억해 놨다가 그 시점부터 계속해서 실행할 수 있게 해야 한다.

문맥 교환은 CPU를 한 프로세스에서 다음 프로세스로 넘겨주는 과정이다.
프로세스가 CPU를 뺏길 때는 레지스터에 저장되어 있던 값, pc값, memory map 을 해당 프로세스의 PCB에 (커널 주소공간의 data에 있는)
CPU를 새로 얻게 된 프로세스도 과거에 CPU를 얻었을 때 실행했던 이력이 있을 것이다. 그 프로세스의 PCB를 찾아서 HW에 저장하고 문맥을 얻어 실행하는 것이다.
✅ 주의 !
context switch는 CPU가 사용자 프로세스 A로부터 사용자 프로세스 B로 넘어가는 것이다.
system call이나 interrupt는 CPU가 사용자 프로세스로부터 OS로 넘어가므로 context switch가 아니다.

(1) 사용자 프로세스 A가 system call을 발생시키거나 인터럽트가 들어옴 -> CPU 제어권이 OS에게 넘어감 -> ISR (interrupt system routine)이나 system call 함수 수행 -> 다시 사용자 프로세스 A에게 CPU가 넘어감
이 상황에서는 문맥교환이 발생하지 않는다.
그냥 프로세스가 user mode -> kerenel mode -> user mode가 된 것이다.
(2) 사용자 프로세스 A가 실행되다가 timer 인터럽트 발생/또는 오래 걸리는 작업인 IO 요청 -> OS에게 CPU 제어권이 넘어감 -> 사용자 프로세스 B에게 CPU 제어권이 넘어감
문맥교환 발생
(1)의 경우, 문맥교환은 일어나지 않지만, CPU가 프로세스 A의 주소공간의 code 부분을 실행하다가, 커널 주소공간의 code를 실행하고, 다시 프로세스 A에게 CPU가 넘어간 것이다. 따라서 CPU 문맥같은 프로세스 문맥의 일부는 PCB에 저장을 해야 한다. 하지만 (2)의 경우처럼 프로세스 자체가 바뀌는 것에 비해서는 훨씬 overhead가 적다.
예) cache memory flush : cache memory는 메인 메모리 윗단의 CPU와 메인 메모리 사이의 빠른 메모리 장치
문맥교환이 일어나게 되면 보통 기존 프로세스가 사용하던 cache memory를 다 지워버려야 한다.(flush)
하지만 (1)의 경우에서는 cache memory를 지울 필요가 없다.
프로세스를 스케쥴링하기 위한 큐
✅ Job Queue
현재 시스템 내에 있는 모든 프로세스의 집합 , 즉 ready queue랑 device queue에 있는 프로세스 포함
✅ Ready Queue
현재 메모리 내에 있으면서 CPU를 잡아서 실행되기를 기다리는 프로세스의 집합
✅ Device Queue
IO device의 처리를 기다리는 프로세스의 집합

실제로는 process 자체가 큐에 줄서있는 것이 아니라 OS가 프로세스를 관리하기 위한 자료구조인 PCB가 줄서있는 것이다. PCB에는 위에서 언급했듯이 pointer가 있어서 그것을 활용해 줄세운다.
스케쥴러
✅ 장기 스케쥴러 Long term scheduler (job scheduler)
메모리를 어떤 프로세스에게 줄 지 결정
프로세스가 처음에 생성되고 (new) 에서 ready가 되기 위해서는 메모리에 올라가야 한다.
롱 텀 스케쥴러가 new 상태의 프로세스에게 메모리를 줄 지 안 줄지 결정한다.
즉 시작 프로세스 중 어떤 것들을 ready queue로 보낼 지 결정
degree of Multiprogramming(메모리 위에 여러 프로그램이 동시에 올라감) 제어
=> 메모리에 올라가있는 프로세스의 수 제어
메모리에 올라간 프로그램의 수를 조절해야 할 필요가 있다.
메모리에 너무 많은 프로그램이 동시에 올라가도 컴퓨터의 성능이 안좋아진다. 왜냐하면 프로그램 당 메모리를 너무 조금씩만 가지고 있게 되어서 당장 실행에 필요한 메모리 조차 할당을 못받기 때문이다.
메모리에 프로그램이 너무 적게 올라가도 성능이 안좋아진다. 메모리에 프로그램이 하나밖에 없다면? 그 프로그램이 CPU를 쓰다가 IO를 하게 가면 CPU가 놀게 되니까..
이러한 이유로 degree of Multiprogramming은 중요한 이슈다.
보통 우리가 사용하는 time sharing system에는 장기 스케쥴러가 없이 프로그램이 실행되면 무조건 ready 상태가 된다.
✅ 단기 스케쥴러 Shor term scheduler (cpu scheduler)
짧은 시간 단위로 스케쥴이 이루어진다. millisecond 단위
어떤 프로세스를 다음 번에 running 시킬지, 즉 어떤 프로세스에게 CPU를 줄 지 결정
✅ 중기 스케쥴러 Medium term scheduler (swapper)
장기 스케쥴러가 없어서 메모리에 너무 많은 프로그램이 올라가 있으면 문제가 된다.
메모리에 너무 많은 프로그램이 동시에 올라가 있으면 여유 공간 마련을 위해 일부 프로세스를 통째로 메모리에서 디스크로 쫓아낸다.
프로세스에서 메모리를 뺏는다
이 방식으로 degree of MultiProgramming 제어
프로세스의 상태 Suspended
✅ Suspended (stopped)
외부적인 이유로(중기 스케쥴러, 사용자 등) 프로세스의 수행이 중지된 상태
중기 스케쥴러 때문에 프로세스가 메모리를 통째로 빼앗긴 상태이다.
또는 사용자가 프로그램을 일시 정지시킨 경우(break key)
프로세스는 통째로 디스크에 swap out 된다
✅ Blocked vs Suspended
Blocked : 자신이 요청한 event가 완료되면 ready
Suspended : 외부에서 resume을 해주어야 active

Suspended가 추가된 프로세스(사용자 프로그램)의 상태도이다.
user mode running : 프로세스가 CPU를 가지고 있으면서 본인의 코드를 실행
moitor(kernel) mode running : OS에게 system call을 해서 운영체제의 코드가 실행중일 때
=> 주의 , 이 상태는 운영체제가 running이라고 하지는 않는다
=> 즉 인터럽트, 트랩, 시스템 콜에 의해 프로세스가 커널 모드에서 running 한다고 간주한다
Suspended도 어느 상태에서 Suspended가 되었는지에 따라 다르게 표현한다.
inactive : 외부적인 이유로 프로세스가 얼어붙은, 정지된 상태
active : inactive 상태에서 외부에서 프로세스를 다시 resume 해주어야 한다. CPU를 얻었거나, 기다리거나, IO를 하거나 프로세스가 뭔가 작업을 하고 있는 상태
다만 Suspended Blocked에서 IO같은 오래걸리는 작업이 진행함에 따라 Suspended Ready로 넘어갈 수는 있다.
(Suspended가 메모리를 Swap out 당해서 CPU 관점에서 아무 일을 못하는 것이고 IO device의 일은 할 수 있으므로)
Thread
스레드는 프로세스 내부의 CPU 수행단위가 여러개 있는 경우
프로세스가 하나 주어지면 code, data, stack으로 구성된 주소공간이 만들어짐
프로세스를 관리하기 위해 OS 내부에 PCB를 둬서 프로세스의 상태를 나타낸다.
동일한 일을 하는 프로세스가 여러개 있다면 프로세스마다 별도의 주소공간이 만들어져서 메모리가 낭비된다
같은 일을 하는 프로세스를 여러개 띄워놓고 싶다
=> 주소공간을 하나만 띄우고 각 프로세스마다 다른 부분의 code를 실행할 수 있게해주면 된다
=> Thread의 개념
프로세스는 하나만 띄워놓고 (code, data, stack)
현재 프로세스가 CPU의 어느 공간을 실행하고 있는가 = PC 만 여러개를 둔다
프로세스 하나에 CPU 수행 단위만 여러개 두고 있는 것을 스레드라고 한다.

각 스레드마다 PC값과 레지스터를 별도로 유지한다.
스레드가 코드를 실행하다가 함수호출을 하면 함수를 호출, 리턴하는 관련 정보를 stack에 쌓아야 하므로 스레드별로 stack도 별도로 둬야 한다.
즉 스레드는 프로세스 하나에서 공유할 수 있는 것 (메모리 주소공간, 프로세스 상태, 프로세스가 사용하는 각종 자원) 등을 최대한 공유하고 CPU 수행과 관련된 정보(PC, 레지스터, stack)을 별도로 관리하는 것이다.
스레드는 CPU를 수행하는 단위다.
스레드의 구성은 PC, register set, stack space이다. (CPU 수행과 관련된)
스레드가 동료 스레드와 공유하는 부분(task)은 code section, data section, OS resources이다.
스레드를 lightweight process라고도 부른다.
프로세스를 별도로 두는 것 보다 프로세스 안에 스레드를 여러개 두는게 더 가볍기 때문
전통적인 프로세스는 heavyweight process라고 부른다.
스레드의 장점
✅ 빠른 응답성 Responsiveness
스레드 하나가 blocked 상태일 때 다른 스레드가 CPU를 잡고 running을 할 수 있어서 응답시간이 빨라진다
웹브라우저에서 웹페이지를 읽어오는 동안(이것 또한 IO이다) 웹브라우저는 blocked 상태가 된다. 사용자는 답답해
웹브라우저에 여러개의 스레드를 사용해 구성해놓으면(multi-threaded Web), 하나의 스레드가 이미지를 불러오는 동안에 다른 스레드가 이미 읽어온 text를 화면에 보여줘 사용자의 답답함을 해소해 줄 수 있다.
스레드를 이용한 일종의 비동기식 입출력, 응답성 향상
✅ 자원 절약 (공유) Resource Sharing
같은 일을 하는 프로세스를 여러개 띄워놓게 되면 각각이 메모리에 올라가야 해서 메모리 낭비가 심하다.
웹브라우저를 여러개 띄웠을 때 각 브라우저마다 각각의 프로세스라면 메모리 낭비
하나의 프로세스로 처리하고 스레드를 여러개 두면 자원을 절약할 수 있다.
✅ 경제성 Economy
프로세스를 하나 만드는 것도 overhead가 크다. 반면 프로세스에 스레드를 추가하는 것은 overhead가 크지 않다.
또한 context swtich는 overhead가 크다. CPU 정보 저장, 캐시 메모리 flush 등..
프로세스 내부에서 스레드 간의 CPU switch가 일어나는 것은 굉장히 간단하다.
대부분의 context는 그대로 사용할 수가 있다.
예) Solaris OS의 경우 overhead가 생성 30배, switch 5배
위 3가지는 CPU가 하나 있는 환경에서도 적용 가능한 장점이다.
✅ 병렬성 Utilization of MP(multiprocessor) Architectures
CPU가 여러개 달린 컴퓨터에서만 해당되는 장점이다.
1000 * 1000 행렬을 곱하는데 각 행, 열을 곱하는 것은 독립적인 연산인데 CPU가 하나밖에 없으면 순차적으로 실행해야 한다. CPU가 여러개 있으면 각각의 행과 열을 곱하는 연산을 서로다른 CPU에서 실행하고 나중에 합쳐주면 더 빠르게 결과를 얻을 수 있다. 이 때 여러개의 스레드를 사용하면 각 스레드들이 서로 다른 CPU에서 실행되며 결과를 빨리 얻을 수 있다.
요약 : 각각의 스레드가 서로 다른 CPU에서 병렬적으로 일을 할 수 있고 결과를 빨리 얻을 수 있다.

스레드가 여러개여도 프로세스는 하나이므로 PCB는 하나만 만들어진다.
스레드가 여러개면 CPU 관련 정보인 PC와 레지스터는 각 스레드 별로 별도로 가지고 있게 된다.
스레드 구현
✅ 커널 스레드
커널을 통해 지원된다.
스레드가 여러개 있다는 사실을 OS 커널이 알고 있다.
하나의 스레드에서 다른 스레드로 CPU가 넘어가는 것도 커널이 CPU 스케쥴링을 하듯이 넘겨준다.
✅ 유저 스레드
라이브러리를 통해 지원된다.
프로세스 안에 스레드가 여러개 있다는 사실을 OS는 모른다. 유저 프로그램이 스스로 여러개의 스레드를 관리한다.
커널이 볼 때는 일반적인 프로세스로 보인다. 프로세스 본인이 내부에서 CPU 수행단위를 여러개 두면서 관리한다.
약간의 제약점은 있을 수 있다.
✅ real time 스레드
그냥 리얼 타임 스레드임
'운영체제 > 운영체제(이화여대)' 카테고리의 다른 글
| DeadLock (9) | 2023.11.10 |
|---|---|
| Process Synchronization (0) | 2023.10.17 |
| CPU scheduling (0) | 2023.10.16 |
| Process Management (1) | 2023.10.16 |
| 운영체제란 무엇인가, 시스템 구조와 프로그램 실행 (0) | 2023.10.10 |

댓글